Publications
-
Hayes, Rao, Akin, Sofroniew, Oktay, Lin, Verkuil, Tran, Deaton, Wiggert, others, Sercu, Candido, Rives. Simulating 500 million years of evolution with a language model. bioRxiv, 2024

-
Verkuil, Kabeli, Du, Wicky, Milles, Dauparas, Baker, Ovchinnikov, Sercu, Rives. Language models generalize beyond natural proteins. bioRxiv, 2022

-
Hie, Candido, Lin, Kabeli, Rao, Smetanin, Sercu, Rives. A high-level programming language for generative protein design. bioRxiv, 2022

-
Lin, Akin, Rao, Hie, Zhu, Lu, Smetanin, Verkuil, Kabeli, Shmueli, others. Evolutionary-scale prediction of atomic-level protein structure with a language model. Science, 2023

-
Hsu, Verkuil, Liu, Lin, Hie, Sercu, Lerer, Rives. Learning inverse folding from millions of predicted structures. bioRxiv, 2022

-
Rao, Liu, Verkuil, Meier, Canny, Abbeel, Sercu, Rives. Msa transformer. Proc. ICML, 2021

-
Meier, Rao, Verkuil, Liu, Sercu, Rives. Language models enable zero-shot prediction of the effects of mutations on protein function. Proc. NeurIPS, 2021

-
Sercu, Robert Verkuil, Joshua Meier, Brandon Amos, Zeming Lin, Caroline Chen, Jason Liu, Yann LeCun, Alexander Rives. Neural Potts Model. Machine Learning for Computational Biology conference, 2020

-
Rives, Meier, Sercu, Goyal, Lin, Liu, Guo, Ott, Zitnick, Ma, others. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. Proceedings of the National Academy of Sciences, 2021

-
Rao, Meier, Sercu, Ovchinnikov, Rives. Transformer protein language models are unsupervised structure learners. Biorxiv, 2020

-
Payel Das, Tom Sercu, Kahini Wadhawan, Inkit Padhi, Sebastian Gehrmann, Flaviu Cipcigan, Vijil Chenthamarakshan, Hendrik Strobelt, Cicero dos Santos, Pin-Yu Chen, Yi Yan Yang, Jeremy Tan, James Hedrick, Jason Crain, Aleksandra Mojsilovic. Accelerated antimicrobial discovery via deep generative models and molecular dynamics simulations. Nature Biomedical Engineering, 2021 [arXiv]

De novo therapeutic design is challenged by a vast chemical repertoire and multiple constraints, e.g., high broad-spectrum potency and low toxicity. We propose CLaSS (Controlled Latent attribute Space Sampling) - an efficient computational method for attribute-controlled generation of molecules, which leverages guidance from classifiers trained on an informative latent space of molecules modeled using a deep generative autoencoder. We screen the generated molecules for additional key attributes by using deep learning classifiers in conjunction with novel features derived from atomistic simulations. The proposed approach is demonstrated for designing non-toxic antimicrobial peptides (AMPs) with strong broad-spectrum potency, which are emerging drug candidates for tackling antibiotic resistance. Synthesis and testing of only twenty designed sequences identified two novel and minimalist AMPs with high potency against diverse Gram-positive and Gram-negative pathogens, including one multidrug-resistant and one antibiotic-resistant K. pneumoniae, via membrane pore formation. Both antimicrobials exhibit low in vitro and in vivo toxicity and mitigate the onset of drug resistance. The proposed approach thus presents a viable path for faster and efficient discovery of potent and selective broad-spectrum antimicrobials.
-
Youssef Mroueh, Tom Sercu, Mattia Rigotti, Inkit Padhi, Cicero Dos Santos. Sobolev Independence Criterion. NeurIPS, 2019 [arXiv]

We propose the Sobolev Independence Criterion (SIC), an interpretable dependency measure between a high dimensional random variable X and a response variable Y . SIC decomposes to the sum of feature importance scores and hence can be used for nonlinear feature selection. SIC can be seen as a gradient regularized Integral Probability Metric (IPM) between the joint distribution of the two random variables and the product of their marginals. We use sparsity inducing gradient penalties to promote input sparsity of the critic of the IPM. In the kernel version we show that SIC can be cast as a convex optimization problem by introducing auxiliary variables that play an important role in feature selection as they are normalized feature importance scores. We then present a neural version of SIC where the critic is parameterized as a homogeneous neural network, improving its representation power as well as its interpretability. We conduct experiments validating SIC for feature selection in synthetic and real-world experiments. We show that SIC enables reliable and interpretable discoveries, when used in conjunction with the holdout randomization test and knockoffs to control the False Discovery Rate. Code is available at http://github.com/ibm/sic.
-
Tom Sercu, Neil Mallinar. Multi-Frame Cross-Entropy Training for Convolutional Neural Networks in Speech Recognition. arXiv:1907.13121, 2019 [arXiv]

We introduce Multi-Frame Cross-Entropy training (MFCE) for convolutional neural network acoustic models. Recognizing that similar to RNNs, CNNs are in nature sequence models that take variable length inputs, we propose to take as input to the CNN a part of an utterance long enough that multiple labels are predicted at once, therefore getting cross-entropy loss signal from multiple adjacent frames. This increases the amount of label information drastically for small marginal computational cost. We show large WER improvements on hub5 and rt02 after training on the 2000-hour Switchboard benchmark.
-
Sercu, Gehrmann, Strobelt, Das, Padhi, Dos Santos, Wadhawan, Chenthamarakshan. Interactive Visual Exploration of Latent Space (IVELS) for peptide auto-encoder model selection. ICLR workshop: Deep Generative Models for Highly Structured Data, 2019

-
Pierre Dognin, Igor Melnyk, Youssef Mroueh, Jerret Ross, Cicero Dos Santos, Tom Sercu. Wasserstein Barycenter Model Ensembling. ICLR, 2019 [arXiv]

In this paper we propose to perform model ensembling in a multiclass or a multilabel learning setting using Wasserstein (W.) barycenters. Optimal transport metrics, such as the Wasserstein distance, allow incorporating semantic side information such as word embeddings. Using W. barycenters to find the consensus between models allows us to balance confidence and semantics in finding the agreement between the models. We show applications of Wasserstein ensembling in attribute-based classification, multilabel learning and image captioning generation. These results show that the W. ensembling is a viable alternative to the basic geometric or arithmetic mean ensembling.
-
Payel Das, Kahini Wadhawan, Oscar Chang, Tom Sercu, Cicero Dos Santos, Matthew Riemer, Vijil Chenthamarakshan, Inkit Padhi, Aleksandra Mojsilovic. Pepcvae: Semi-supervised targeted design of antimicrobial peptide sequences. arXiv:1810.07743, 2018 [arXiv]

Given the emerging global threat of antimicrobial resistance, new methods for next-generation antimicrobial design are urgently needed. We report a peptide generation framework PepCVAE, based on a semi-supervised variational autoencoder (VAE) model, for designing novel antimicrobial peptide (AMP) sequences. Our model learns a rich latent space of the biological peptide context by taking advantage of abundant, unlabeled peptide sequences. The model further learns a disentangled antimicrobial attribute space by using the feedback from a jointly trained AMP classifier that uses limited labeled instances. The disentangled representation allows for controllable generation of AMPs. Extensive analysis of the PepCVAE-generated sequences reveals superior performance of our model in comparison to a plain VAE, as PepCVAE generates novel AMP sequences with higher long-range diversity, while being closer to the training distribution of biological peptides. These features are highly desired in next-generation antimicrobial design.
-
Chun-Fu Chen, Quanfu Fan, Neil Mallinar, Tom Sercu, Rogerio Feris. Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition. ICLR, 2019 [arXiv]

In this paper, we propose a novel Convolutional Neural Network (CNN) architecture for learning multi-scale feature representations with good tradeoffs between speed and accuracy. This is achieved by using a multi-branch network, which has different computational complexity at different branches. Through frequent merging of features from branches at distinct scales, our model obtains multi-scale features while using less computation. The proposed approach demonstrates improvement of model efficiency and performance on both object recognition and speech recognition tasks,using popular architectures including ResNet and ResNeXt. For object recognition, our approach reduces computation by 33% on object recognition while improving accuracy with 0.9%. Furthermore, our model surpasses state-of-the-art CNN acceleration approaches by a large margin in accuracy and FLOPs reduction. On the task of speech recognition, our proposed multi-scale CNNs save 30% FLOPs with slightly better word error rates, showing good generalization across domains. The codes are available at https://github.com/IBM/BigLittleNet
-
Youssef Mroueh, Tom Sercu, Anant Raj. Sobolev Descent. AISTATS, 2019 [arXiv]

We study a simplification of GAN training: the problem of transporting particles from a source to a target distribution. Starting from the Sobolev GAN critic, part of the gradient regularized GAN family, we show a strong relation with Optimal Transport (OT). Specifically with the less popular dynamic formulation of OT that finds a path of distributions from source to target minimizing a ``kinetic energy''. We introduce Sobolev descent that constructs similar paths by following gradient flows of a critic function in a kernel space or parametrized by a neural network. In the kernel version, we show convergence to the target distribution in the MMD sense. We show in theory and experiments that regularization has an important role in favoring smooth transitions between distributions, avoiding large gradients from the critic. This analysis in a simplified particle setting provides insight in paths to equilibrium in GANs.
-
Pierre L. Dognin, Igor Melnyk, Youssef Mroueh, Jarret Ross, Tom Sercu. Adversarial Semantic Alignment for Improved Image Captions. arXiv:1805.00063, 2018 [arXiv]

In this paper we study image captioning as a conditional GAN training, proposing both a context-aware LSTM captioner and co-attentive discriminator, which enforces semantic alignment between images and captions. We empirically focus on the viability of two training methods: Self-critical Sequence Training (SCST) and Gumbel Straight-Through (ST) and demonstrate that SCST shows more stable gradient behavior and improved results over Gumbel ST, even without accessing discriminator gradients directly. We also address the problem of automatic evaluation for captioning models and introduce a new semantic score, and show its correlation to human judgement. As an evaluation paradigm, we argue that an important criterion for a captioner is the ability to generalize to compositions of objects that do not usually co-occur together. To this end, we introduce a small captioned Out of Context (OOC) test set. The OOC set, combined with our semantic score, are the proposed new diagnosis tools for the captioning community. When evaluated on OOC and MS-COCO benchmarks, we show that SCST-based training has a strong performance in both semantic score and human evaluation, promising to be a valuable new approach for efficient discrete GAN training.
-
Tom Sercu, Youssef Mroueh. Semi-Supervised Learning with IPM-based GANs: an Empirical Study. NIPS Workshop: Deep Learning: Bridging Theory and Practice, 2017 [arXiv]

We present an empirical investigation of a recent class of Generative Adversarial Networks (GANs) using Integral Probability Metrics (IPM) and their performance for semi-supervised learning. IPM-based GANs like Wasserstein GAN, Fisher GAN and Sobolev GAN have desirable properties in terms of theoretical understanding, training stability, and a meaningful loss. In this work we investigate how the design of the critic (or discriminator) influences the performance in semi-supervised learning. We distill three key take-aways which are important for good SSL performance: (1) the K+1 formulation, (2) avoiding batch normalization in the critic and (3) avoiding gradient penalty constraints on the classification layer.
-
Youssef Mroueh, Chun-Liang Li, Tom Sercu, Anant Raj, Yu Cheng. Sobolev GAN. ICLR, 2018 [arXiv]

We propose a new Integral Probability Metric (IPM) between distributions: the Sobolev IPM. The Sobolev IPM compares the mean discrepancy of two distributions for functions (critic) restricted to a Sobolev ball defined with respect to a dominant measure $\mu$. We show that the Sobolev IPM compares two distributions in high dimensions based on weighted conditional Cumulative Distribution Functions (CDF) of each coordinate on a leave one out basis. The Dominant measure $\mu$ plays a crucial role as it defines the support on which conditional CDFs are compared. Sobolev IPM can be seen as an extension of the one dimensional Von-Mises Cram\'er statistics to high dimensional distributions. We show how Sobolev IPM can be used to train Generative Adversarial Networks (GANs). We then exploit the intrinsic conditioning implied by Sobolev IPM in text generation. Finally we show that a variant of Sobolev GAN achieves competitive results in semi-supervised learning on CIFAR-10, thanks to the smoothness enforced on the critic by Sobolev GAN which relates to Laplacian regularization.
-
Youssef Mroueh, Tom Sercu. Fisher GAN. NIPS, 2017 [arXiv]

Generative Adversarial Networks (GANs) are powerful models for learning complex distributions. Stable training of GANs has been addressed in many recent works which explore different metrics between distributions. In this paper we introduce Fisher GAN which fits within the Integral Probability Metrics (IPM) framework for training GANs. Fisher GAN defines a critic with a data dependent constraint on its second order moments. We show in this paper that Fisher GAN allows for stable and time efficient training that does not compromise the capacity of the critic, and does not need data independent constraints such as weight clipping. We analyze our Fisher IPM theoretically and provide an algorithm based on Augmented Lagrangian for Fisher GAN. We validate our claims on both image sample generation and semi-supervised classification using Fisher GAN.
-
George Saon, Gakuto Kurata, Tom Sercu, Kartik Audhkhasi, Samuel Thomas, Dimitrios Dimitriadis, Xiaodong Cui, Bhuvana Ramabhadran, Michael Picheny, Lynn-Li Lim, Bergul Roomi, Phil Hall. English conversational telephone speech recognition by humans and machines. Proc Interspeech, 2017 [arXiv]

One of the most difficult speech recognition tasks is accurate recognition of human to human communication. Advances in deep learning over the last few years have produced major speech recognition improvements on the representative Switchboard conversational corpus. Word error rates that just a few years ago were 14% have dropped to 8.0%, then 6.6% and most recently 5.8%, and are now believed to be within striking range of human performance. This then raises two issues - what IS human performance, and how far down can we still drive speech recognition error rates? A recent paper by Microsoft suggests that we have already achieved human performance. In trying to verify this statement, we performed an independent set of human performance measurements on two conversational tasks and found that human performance may be considerably better than what was earlier reported, giving the community a significantly harder goal to achieve. We also report on our own efforts in this area, presenting a set of acoustic and language modeling techniques that lowered the word error rate of our own English conversational telephone LVCSR system to the level of 5.5%/10.3% on the Switchboard/CallHome subsets of the Hub5 2000 evaluation, which - at least at the writing of this paper - is a new performance milestone (albeit not at what we measure to be human performance!). On the acoustic side, we use a score fusion of three models: one LSTM with multiple feature inputs, a second LSTM trained with speaker-adversarial multi-task learning and a third residual net (ResNet) with 25 convolutional layers and time-dilated convolutions. On the language modeling side, we use word and character LSTMs and convolutional WaveNet-style language models.
-
Sercu, Saon, Cui, Cui, Ramabhadran, Kingsbury, Sethy. Network architectures for multilingual speech representation learning. Proc ICASSP, 2017

-
Youssef Mroueh, Tom Sercu, Vaibhava Goel. McGan: Mean and Covariance Feature Matching GAN. ICML, 2017 [arXiv]

We introduce new families of Integral Probability Metrics (IPM) for training Generative Adversarial Networks (GAN). Our IPMs are based on matching statistics of distributions embedded in a finite dimensional feature space. Mean and covariance feature matching IPMs allow for stable training of GANs, which we will call McGan. McGan minimizes a meaningful loss between distributions.
-
Tom Sercu, Vaibhava Goel. Dense Prediction on Sequences with Time-Dilated Convolutions for Speech Recognition. NIPS End-to-end Learning for Speech and Audio Processing Workshop, 2016 [arXiv]

In computer vision pixelwise dense prediction is the task of predicting a label for each pixel in the image. Convolutional neural networks achieve good performance on this task, while being computationally efficient. In this paper we carry these ideas over to the problem of assigning a sequence of labels to a set of speech frames, a task commonly known as framewise classification. We show that dense prediction view of framewise classification offers several advantages and insights, including computational efficiency and the ability to apply batch normalization. When doing dense prediction we pay specific attention to strided pooling in time and introduce an asymmetric dilated convolution, called time-dilated convolution, that allows for efficient and elegant implementation of pooling in time. We show results using time-dilated convolutions in a very deep VGG-style CNN with batch normalization on the Hub5 Switchboard-2000 benchmark task. With a big n-gram language model, we achieve 7.7% WER which is the best single model single-pass performance reported so far.
-
George Saon, Tom Sercu, Steven Rennie, Hong-Kwang J. Kuo. The IBM 2016 English Conversational Telephone Speech Recognition System. Proc Interspeech, 2016 [arXiv]
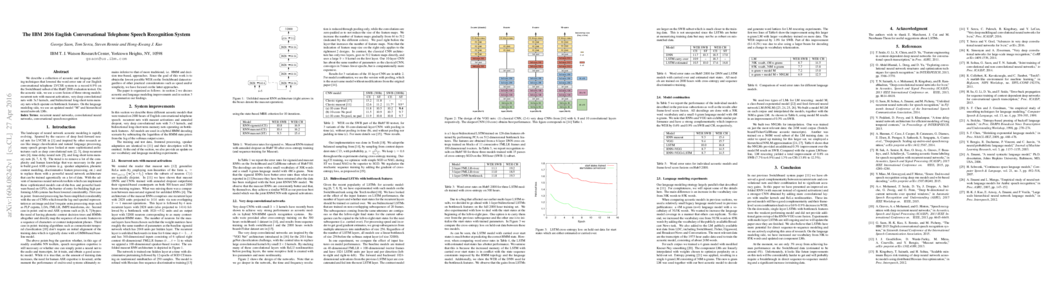
We describe a collection of acoustic and language modeling techniques that lowered the word error rate of our English conversational telephone LVCSR system to a record 6.6% on the Switchboard subset of the Hub5 2000 evaluation testset. On the acoustic side, we use a score fusion of three strong models: recurrent nets with maxout activations, very deep convolutional nets with 3x3 kernels, and bidirectional long short-term memory nets which operate on FMLLR and i-vector features. On the language modeling side, we use an updated model "M" and hierarchical neural network LMs.
-
Tom Sercu, Vaibhava Goel. Advances in Very Deep Convolutional Neural Networks for LVCSR. Proc Interspeech, 2016 [arXiv]

Very deep CNNs with small 3x3 kernels have recently been shown to achieve very strong performance as acoustic models in hybrid NN-HMM speech recognition systems. In this paper we investigate how to efficiently scale these models to larger datasets. Specifically, we address the design choice of pooling and padding along the time dimension which renders convolutional evaluation of sequences highly inefficient. We propose a new CNN design without timepadding and without timepooling, which is slightly suboptimal for accuracy, but has two significant advantages: it enables sequence training and deployment by allowing efficient convolutional evaluation of full utterances, and, it allows for batch normalization to be straightforwardly adopted to CNNs on sequence data. Through batch normalization, we recover the lost peformance from removing the time-pooling, while keeping the benefit of efficient convolutional evaluation. We demonstrate the performance of our models both on larger scale data than before, and after sequence training. Our very deep CNN model sequence trained on the 2000h switchboard dataset obtains 9.4 word error rate on the Hub5 test-set, matching with a single model the performance of the 2015 IBM system combination, which was the previous best published result.
-
Tom Sercu, Christian Puhrsch, Brian Kingsbury, Yann LeCun. Very deep multilingual convolutional neural networks for LVCSR. Proc ICASSP, 2015 [arXiv]

Convolutional neural networks (CNNs) are a standard component of many current state-of-the-art Large Vocabulary Continuous Speech Recognition (LVCSR) systems. However, CNNs in LVCSR have not kept pace with recent advances in other domains where deeper neural networks provide superior performance. In this paper we propose a number of architectural advances in CNNs for LVCSR. First, we introduce a very deep convolutional network architecture with up to 14 weight layers. There are multiple convolutional layers before each pooling layer, with small 3x3 kernels, inspired by the VGG Imagenet 2014 architecture. Then, we introduce multilingual CNNs with multiple untied layers. Finally, we introduce multi-scale input features aimed at exploiting more context at negligible computational cost. We evaluate the improvements first on a Babel task for low resource speech recognition, obtaining an absolute 5.77% WER improvement over the baseline PLP DNN by training our CNN on the combined data of six different languages. We then evaluate the very deep CNNs on the Hub5'00 benchmark (using the 262 hours of SWB-1 training data) achieving a word error rate of 11.8% after cross-entropy training, a 1.4% WER improvement (10.6% relative) over the best published CNN result so far.
subscribe via RSS